Design¶
This prototype follows the overall structure proposed in Wortmann, (2017). We only consider the predict and not the backwards step – meaning that we go from a sky image to visibilities, but not the other way around. This means that we end up with two stages as shown below.
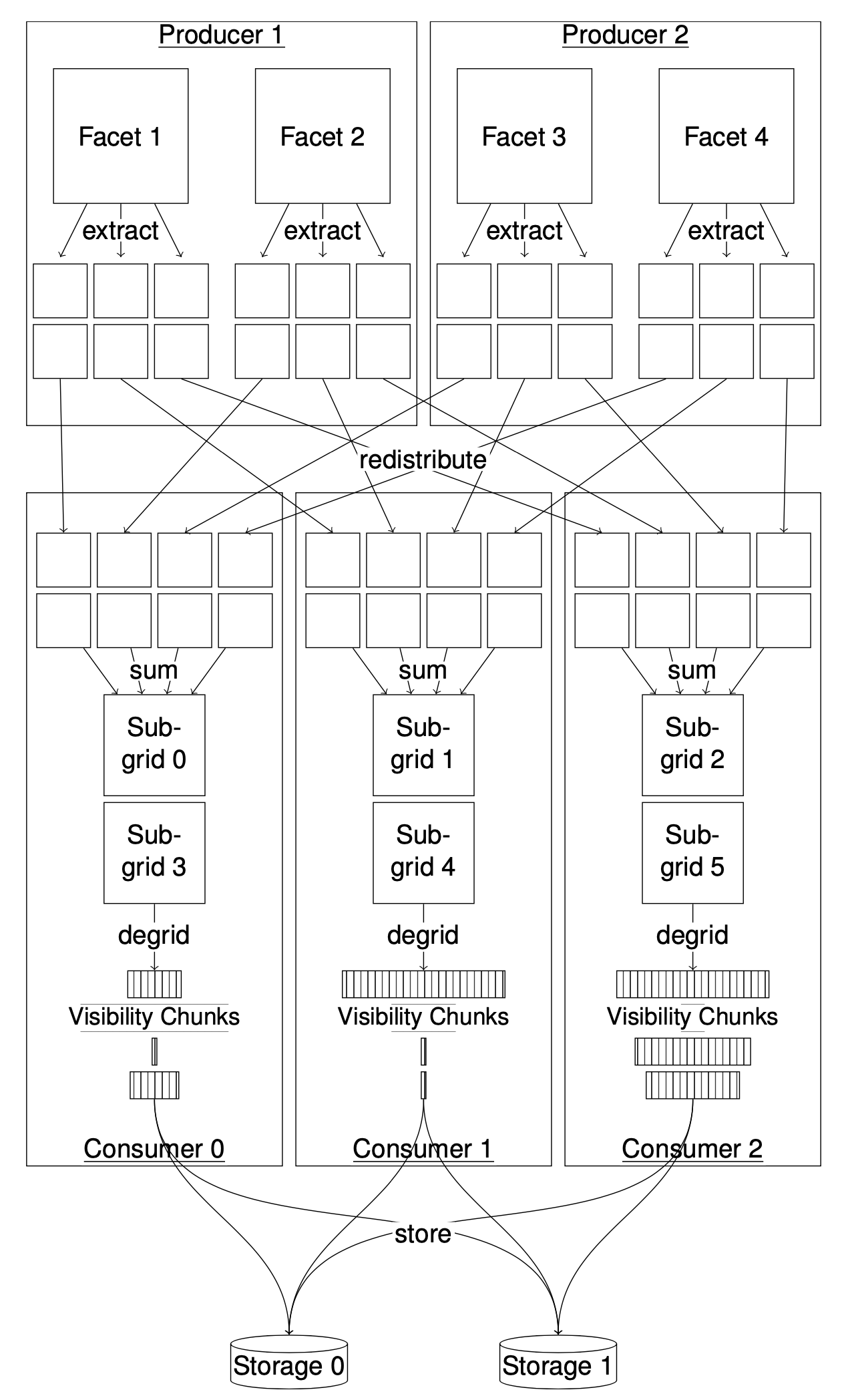
The idea is that we split the program into distributed processes, with both “producer” and “streamer” processes present and active on all participating throughout the run. This means that there is a continuous data re-distribution between the two steps, where we re-shuffle all relevant image data to get into the grid domain.
The way this works, producer processes hold some portion of the image data (facets). Collectively this represents a lot of data, up to a few terabytes for SKA-sized imaging cases. Instead of attempting to do a full Fourier Transform of this data to obtain the uv-grid, we instead re-construct sub-grid cut-outs sequentially until we have covered all relevant regions of the grid. This means that image data stays in place, and all producer processes walk through the grid in the same pre-determined fashion, streaming out sub-grid contributions to streamer processes.
Streamer processes collect these contributions from producer processes and assemble complete sub-grids (cut-outs of the entire grid). Each such sub-grid can then be used for de-gridding visibilities. The amount of visibility data that can be extracted from a given subgrid varies dramatically depending on the sub-grid position: A sub-grid near the centre of the grid will both overlap more baselines, and tend to cover bigger windows in time and frequency.
Work Balance¶
Facet and subgrid work is assigned to producer and streamer processes at the start of the run. Facets are large memory objects, and the same amount of work needs to be done on each of them, therefore the number of nodes should be chosen so we can distribute them evenly - ideally the number of nodes should be the same as the number of facets.
On the other hand, each subgrid will be used to de-grid a different number of baselines and therefore visibilities depending on the grid area covered. This has to be balanced, keeping in mind that we want a healthy mix of subgrids to visibility chunks so the streamer doesn’t run into a bottleneck on the network side of things. Right now we use a simple round-robin scheduling, splitting the work in central subgrids among nodes past a certain threshold. Parallelism
Both producer and streamer scale to many cores. The facet side of recombination / phase rotation is essentially a distributed FFT that we do separately on two axes, which leads to ample parallelism opportunities. However in order to keep memory residency manageable it is best to work on subgrid columns sequentially. Subgrid work is scheduled in rough column order to accomodate this.
The streamer employs three types of threads: One to receive data from the network and sum up subgrids, one to write visibilities as HDF5 (we serialise this for simplicity), and the rest to degrid baseline visibilities from subgrids. The network thread generally has very little work and will spawn a lot of tasks very quickly, which means that OpenMP will often have it yield to worker threads, effectively making it a worker thread.
Queues¶
In order to get good throughput every stage has input and output queues. We employ slightly different mechanisms depending on stage:
The producer has only limited MPI slots per thread to send out subgrid contributions (current default: 8 subgrids worth)
On the other end, the streamer has a limited number of MPI slots to receive facet contributions (current default: 32 subgrids worth)
The network thread will assemble sub-grids once all contributions have been received, and create OpenMP tasks for degridding. The subgrids in question will be locked until all de-grid tasks have been finished, the queue is limited to the same number of entries as the incoming facet contribution queue (so 32 entries).
OpenMP limits the number of degrid tasks that can be spawned, which means that we additionally have a degrid task queue with limited capacity (Seems to be around 128 for gcc). Note that a task can cover many baselines (current default is up to 256 - so roughly 32768 baselines maximum).
Finally, once visibilities have been generated, those will have to be written out. This is done in terms of visibility chunks (size configurable, the - low - default is currently 32x32). The queue has a length of 32768 entries (roughly half a GB worth of data with default parameters).